.splitterAI est un modèle d’IA permettant de découper très précisément un dossier ou un pli en pièces individuelles.
Qu’il s’agisse d’un dossier nativement numérique ou de la numérisation d’un pli de courrier papier, le modèle va automatiquement séparer le fichier d’origine en documents individuels d’une ou plusieurs pages.
Chaque découpe a un score de fiabilité et l’interface d’arbitrage de Provence.ai permet de résoudre les ambiguïtés remontées par l’IA.
La technologie de séparation des pièces n’a pas de limite sur la taille ou le nombre de pages du fichier d’origine, et les pièces correctement découpées sont retournées au format PDF. Pour entraîner le modèle de découpe de fichier, il suffit de lui fournir entre 50 et 100 exemplaires de chaque pièce individuelle.
La performance constatée en production dépasse 98.5% sur des fichiers hétérogènes. Cette fonctionnalité de découpe automatique par IA est accessible en API ou sur la plate-forme Provence.ai.

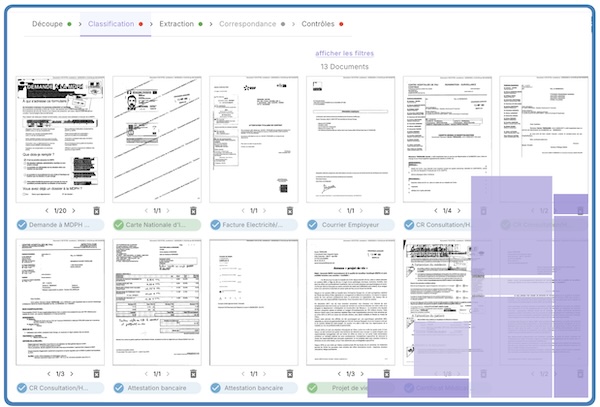
Sur des flux documentaires variés et complexes, il est critique de pouvoir trier et classer les pièces avec un très haut niveau de fiabilité.
L’indexation automatique de fichiers par IA atteint en production un taux de fiabilité supérieur à 99.5%.
Le modèle d’IA pour l’identification d’un document (PDF ou image) combine différents modèles de reconnaissance, avec des transformeurs de vision et de traitement du langage.
Le modèle de classification de fichiers ou de pièces peut s’appliquer sur un flux courant avec une très faible latence (<90ms par page) ou sur un stock historique de documents.
Pour entraîner un modèle d’IA de classement documentaire, il suffit de lui fournir entre 20 et 100 exemplaires de chaque type de document. Il n’y a aucune limite sur le nombre de pages de chaque document, ou sur le nombre de types de pièces que peut gérer l’IA : plus la classification est granulaire (fine), plus le modèle est performant.
Chaque segmentation de pièce donne lieu à un score de lisibilité et à un score de confiance, permettant de soumettre le résultat à l’arbitrage et d’améliorer le modèle d’IA. Ce service est accessible en API ou sur la plate-forme Provence.ai.
Les modèles d’Intelligence Artificielle utilisent plusieurs couches de reconnaissance (OCR, HCR, ICR) pour l’extraction avancée de données (ou métadonnées).
Notre technologie est particulièrement performante sur :
- L’extraction des textes manuscrits (voir notre étude).
- L'extraction des documents de qualité hétérogène (qualité, orientation, variations, documents déstructurés) comme les photos, les scans médiocres, les lettres au format libre, etc.
- Le traitement des documents formatés à la structuration complexe (formulaires) comportant des cases à cocher, des tableaux, des code barres, etc.
- La détection d’éléments visuels à placement libre (ie. une signature, un tampon ou une annotation peuvent être n'importe où).
- La détection d’éléments superposés (par exemple distinguer une signature appliquée sur un tampon).

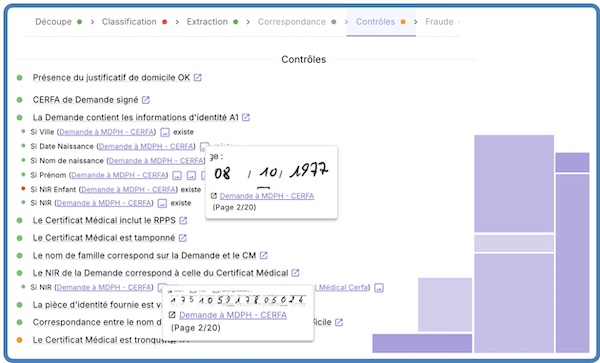
Le moteur de contrôles a pour objectif de croiser des données et des pièces pour s’assurer de la complétude, de la conformité ou de la cohérence d’un dossier (lot de pièces) ou d’un document.
Le module de contrôles de Provence.ai permet une infinité de comparaisons entre des types de documents et des données, par exemple :
- Un contrat de bail contient-il a minima les signatures du bailleur et du locataire ?
- L'adresse d’un justificatif est-elle comparable (à l’approchant) à celle d’une pièce d’identité ?
- Si la case « tutelle » est cochée sur un formulaire, le pli ou le dossier contient-il bien un jugement de tutelle ?
- S’il existe un tampon de médecin sur un certificat, peut-on bien extraire son numéro RPPS du tampon ?
Certains contrôles peuvent être obligatoires ou simplement informatifs. Lorsque les contrôles ont été configurés, ils sont accessibles par API ou dans l’application.
Le module de détection de falsification documentaire par IA a pour objectif de détecter toute forme de modification d’un document dans le but de tromper le lecteur ou obtenir des droits indûs.
Si l’objectif est de détecter le maximum des documents altérés ou compromis, il est crucial de restreindre le taux de faux positifs.
Pour détecter les fraudes, Provence.ai a conçu un enchaînement de dizaines de traitements par IA pour :
- Détecter les logiciels ou les appareils utilisés pour éditer le document.
- Détecter les contenus modifiés, remplacés, déplacés dans le document, en les recoupants avec les « zones d’intérêt » issues des moteurs d’extraction de données.
- Détecter les altérations et modifications sur les documents non nativement digitaux, comme par exemple un document papier scanné, la photo d’un document imprimé [expérimental].
- Détecter les variations significatives sur un jeu de documents vérifiés.
- Enrichir un modèle entraîné sur des documents dont la falsification est avérée.
En couplant le module de contrôle d’incohérences avec ce module de fraude documentaire IA, Provence.ai propose la solution la plus complète, de bout en bout, pour la vérification de dossiers.Si l’objectif est de détecter le maximum des documents altérés ou compromis, il est crucial de restreindre le taux de faux positifs.

